我的文档集
我们在使用大模型时通常会面临这两个问题:
由于大语言模型的训练成本较高,训练数据无法实时更新,这导致当您需要大模型回答最新或涉及企业专业领域知识的问题时,由于缺乏相关知识,大模型无法提供准确的答案。
每次请求的上下文有长度限制,你无法将大量知识库内容放在prompt中。
为了解决这些挑战,我们使用嵌入模型(embedding)+向量数据库+搜索策略,搭建了这套语义搜索引擎,并在文档集的相关功能中呈现。通过该功能,我们能够为应用程序提供更全面的上下文支持,从而提升大模型输出内容的质量。文档管理功能允许您将各种文档和知识库与大模型进行关联,并将其嵌入到模型的训练和推理过程中。这样一来,大模型可以在回答问题时更好地利用文档中的信息,以便提供更准确、全面的答案。
支持两种数据引入方式:上传本地文件、插入文件地址
上传文档支持两大类型:
非结构化文档:指不具备明确格式、结构和关系的文档,比如,产品操作手册、电子邮件、图片、文章、书籍等,文档形式包括 Pdf、Word、Txt、图片等。
结构化文档:指有明确格式、结构、分类和关系的文档。如有固定表头的excel、csv、jsonl等
情景:如果你想基于现有知识库和产品文档建立一个 AI 客服助手,你可以将文档上传至文档集,并建立一个对话型或搜索型应用。这在过去可能需要花费很多时间,且难以持续维护。
文档集与文档 #
在天壤小白开放平台中,文档集(Datasets)是一些文档(Documents)的集合。一个文档集可以被整体集成至一个应用中作为上下文使用。文档可以由开发者或运营人员上传。
上传文档的步骤:
上传你的文件,通常是长文本文件或表格文件。
分段、清洗并预览。
系统自动调用 embedding 模型将文本内容嵌入为向量数据,并存储。
可以在应用中使用了🎉!
创建文档集 #
在小白开放平台主导航栏中点击文档集,在该页面你可以看到已有的文档集。你可以点击创建文档集进入创建向导:
如果你已经准备好了文件,可以从上传文件开始。
如果你还没有准备好文档,可以先创建一个空文档集。
上传文件 #
你可以直接上传本地文件,或填入一个获取文件的地址。
方式1:填入一个公开网页链接
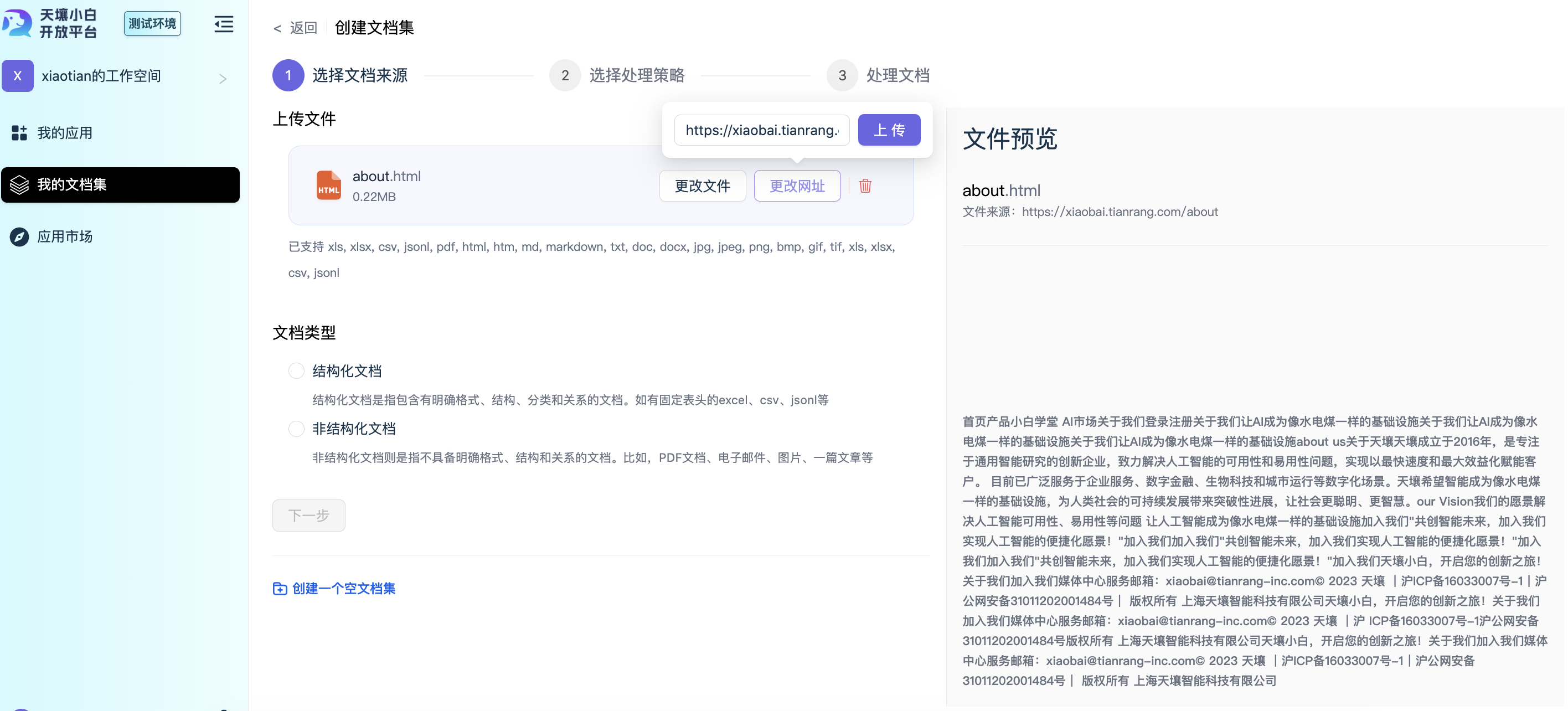
方式2:上传一个结构化文档
如:原文件是一个有表头,包含QA两列数据的excel文件

上传后,你可以预览全文,并在文档类型中选择「结构化文档」

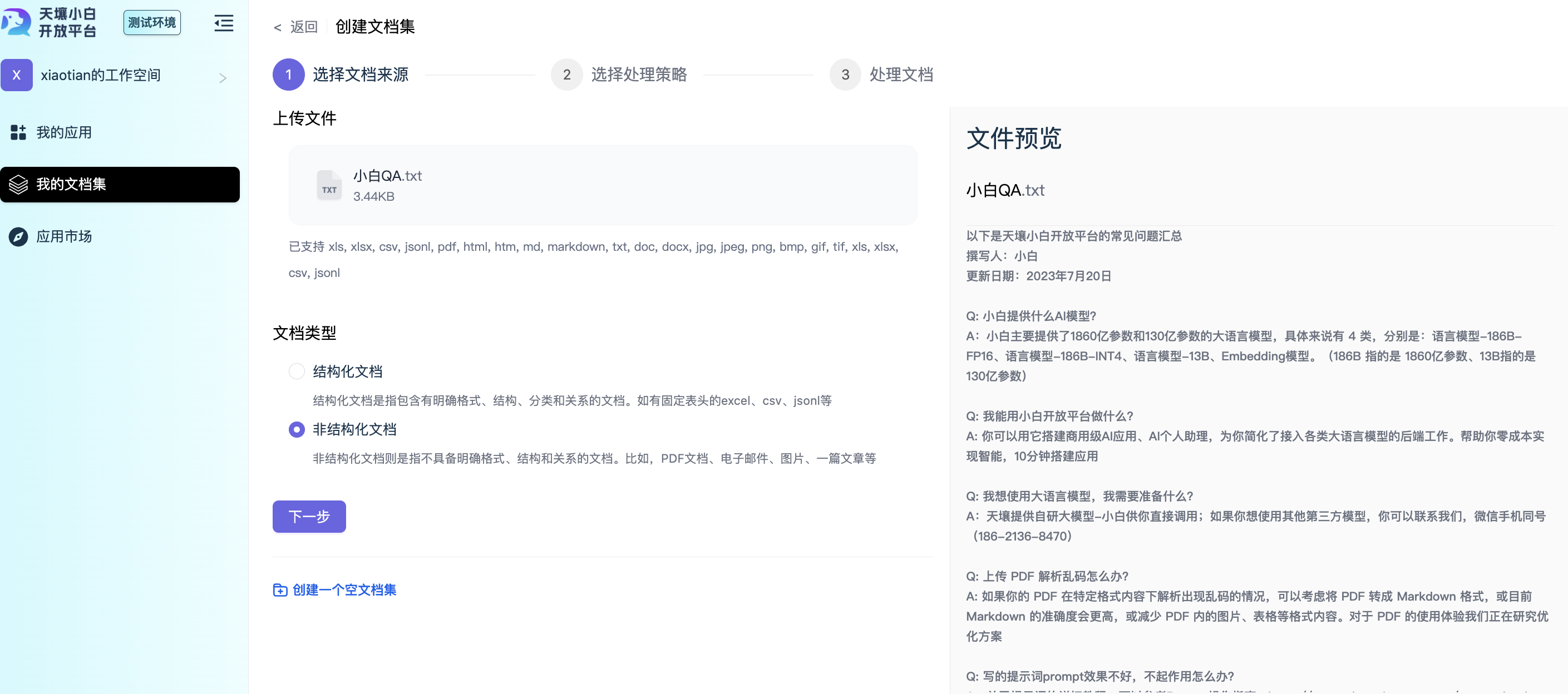
方式3:上传一个非结构化文档
如:原文件是一个包含QA和其他介绍信息的TXT文档

上传后,你可以预览全文,并在文档类型中选择「非结构化文档」
选择处理策略 #
对结构化文档的处理策略
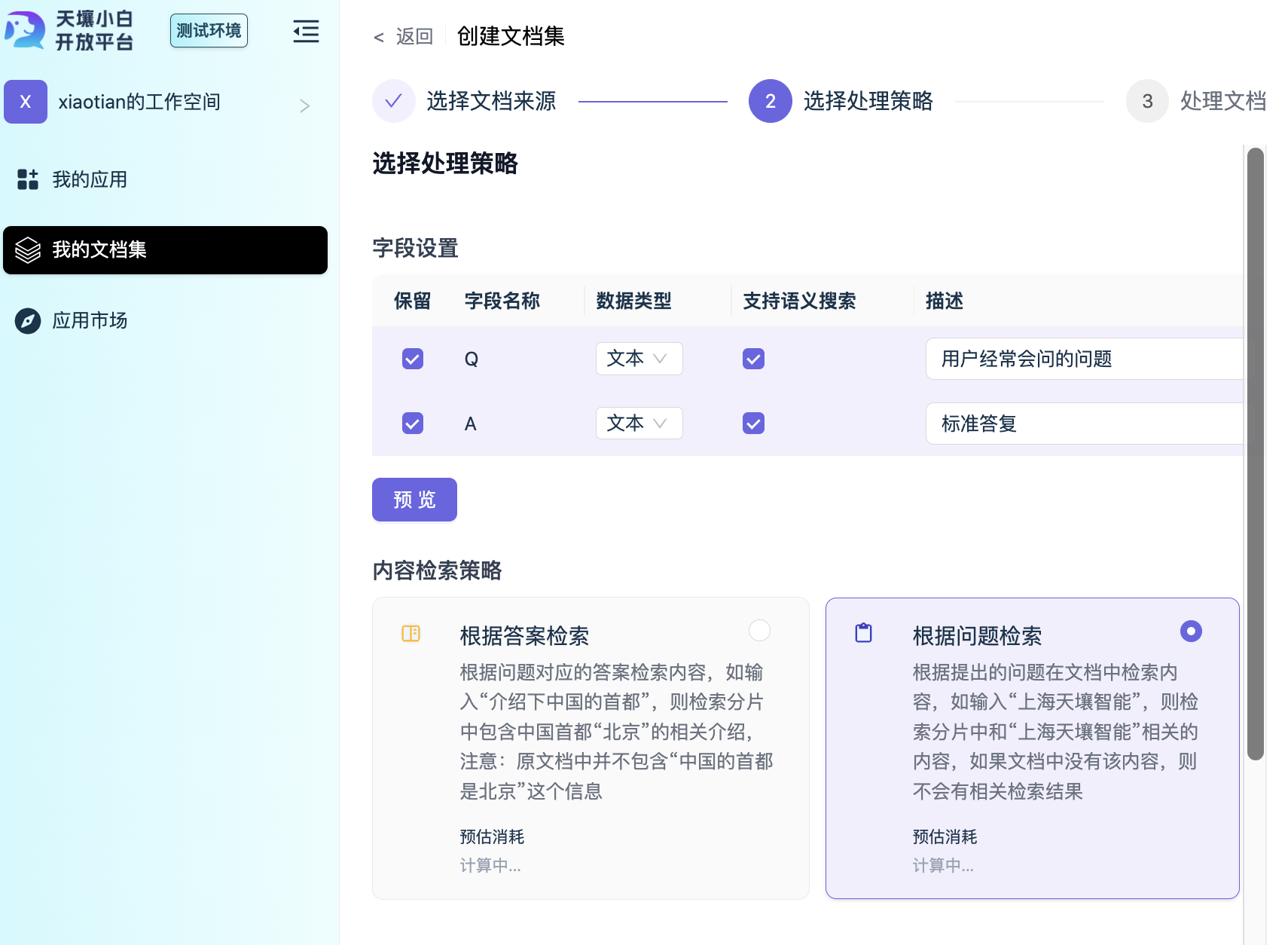
字段设置
- 勾选需要保留的字段
- 设置字段的数据类型(文本/数字/整数/布尔/)
- 设置字段是否支持被搜索
内容检索策略
- 根据答案检索:根据问题对应的答案检索内容,如输入“介绍下中国的首都”,则检索分片中包含中国首都“北京”的相关介绍,注意:原文档中并不包含“中国的首都是北京”这个信息。
- 根据问题检索:根据提出的问题在文档中检索内容,如输入“上海天壤智能”,则检索分片中和“上海天壤智能”这段文本相似的内容,如果文档中没有相似的内容,则不会有相关检索结果。
如果你的文档是Q&A这样的知识库内容,并且以结构化文档的方式上传,在大部分情况下,使用 「根据问题检索」 效果会更好。
对非结构化文档的处理策略
分片存储策略
默认分片存储:系统自行处理,使用者无需关心。
定制分片存储:通过调整分片参数可以达到所需分片的最佳效果。有三个参数可配置,这些参数配置的执行顺序是:
第一步:根据「分片标记」中设置的符号/字符,对文档进行拆分;
第二步:再看相邻分片合并是否超出「每个分片最大长度」,如果没有超出,会将相邻分片合并,在合并的时候根据「相邻分片的重叠长度」进行合并,并使得最后每个分片长度尽可能接近「每个分片最大长度」,以保证每片的长度是可控且相近的。
第三步:对合并后的分片,去除文本最后的分片符号
注:「相邻分片重叠」指的是代表相邻两个分片中,前一个分片末尾字符与后一个分钱的起始字符的相同部分,这个部分相同的字符数即代表「相邻分片重叠长度」。
【案例1】
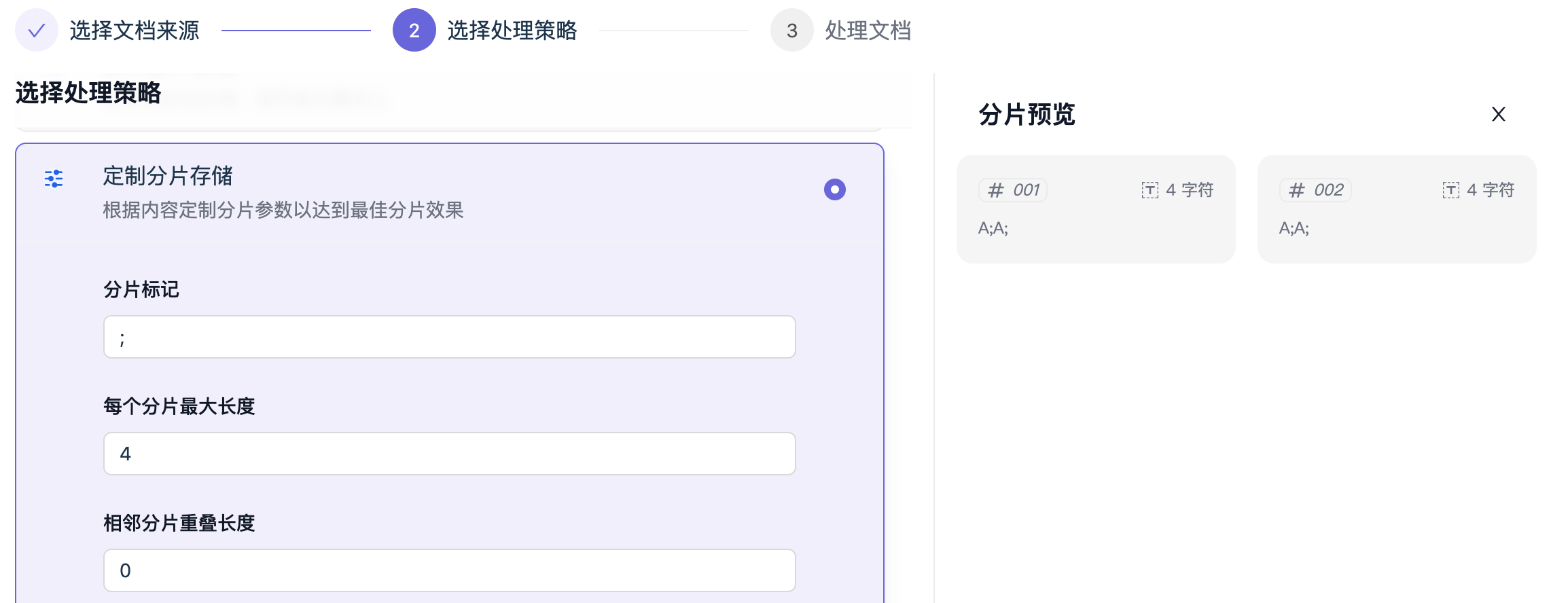 上图示例中:分片标记设为分号 ; 每片最大长度设为 4,相邻分片重叠长度为0,要切分 A;B;C;D 。执行顺序是:
上图示例中:分片标记设为分号 ; 每片最大长度设为 4,相邻分片重叠长度为0,要切分 A;B;C;D 。执行顺序是:1️⃣ 按照分号把 A;B;C;D 分成了 4个切片,分别是 [A][B][C][D]
2️⃣ 发现两个切片合并后(带原有分隔符)的长度等于4
3️⃣ 进行两两合并,去除最后的分隔符,分为[A;B] 和 [C;D] 两片
【案例2】
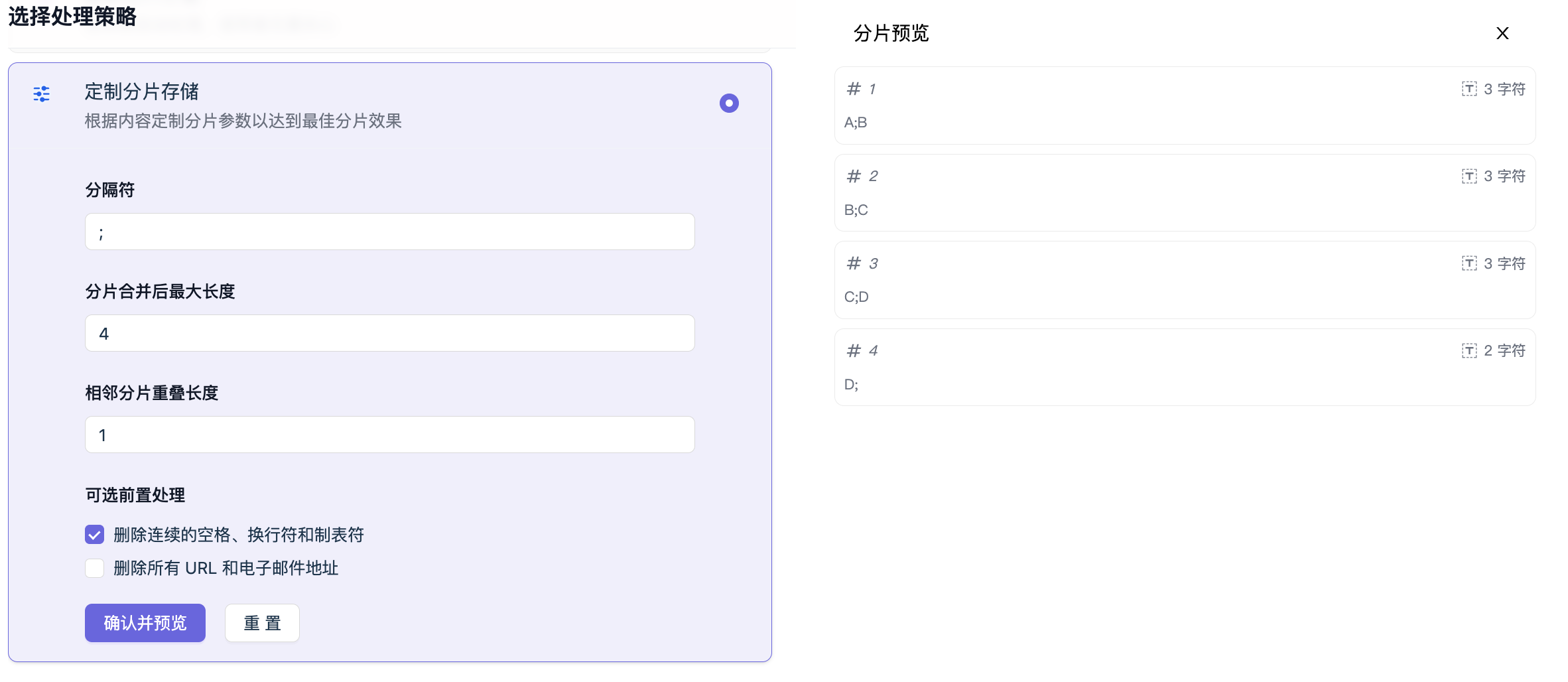 上图示例中:分片标记设为分号 ; 每片最大长度设为 4,相邻分片重叠长度为1,要切分 A;B;C;D 。执行顺序是:
上图示例中:分片标记设为分号 ; 每片最大长度设为 4,相邻分片重叠长度为1,要切分 A;B;C;D 。执行顺序是:1️⃣ 按照分号把 A;B;C;D 分成了 4个切片,分别是 -> [A][B][C][D]
2️⃣ 试图合并相邻切片,发现合并后(带原有分隔符)的长度不超过4,并且要求重叠长度是1
3️⃣ 进行两两合并,相邻片段重叠,去除最后的分隔符,分为[A;B][B;C][C;D] 和 [D;] 共4片
内容检索策略
- 根据答案检索:根据问题对应的答案检索内容,如输入“介绍下中国的首都”,则检索分片中包含中国首都“北京”的相关介绍,注意:原文档中并不包含“中国的首都是北京”这个信息。
- 根据问题检索:根据提出的问题在文档中检索内容,如输入“上海天壤智能”,则检索分片中和“上海天壤智能”这段文本相似的内容,如果文档中没有相似的内容,则不会有相关检索结果。
如果你的文档内容没有固定格式的(比如产品操作手册),这样的知识库内容,并且以非结构化文档的方式上传,在大部分情况下,使用 「根据答案检索」 效果会更好。
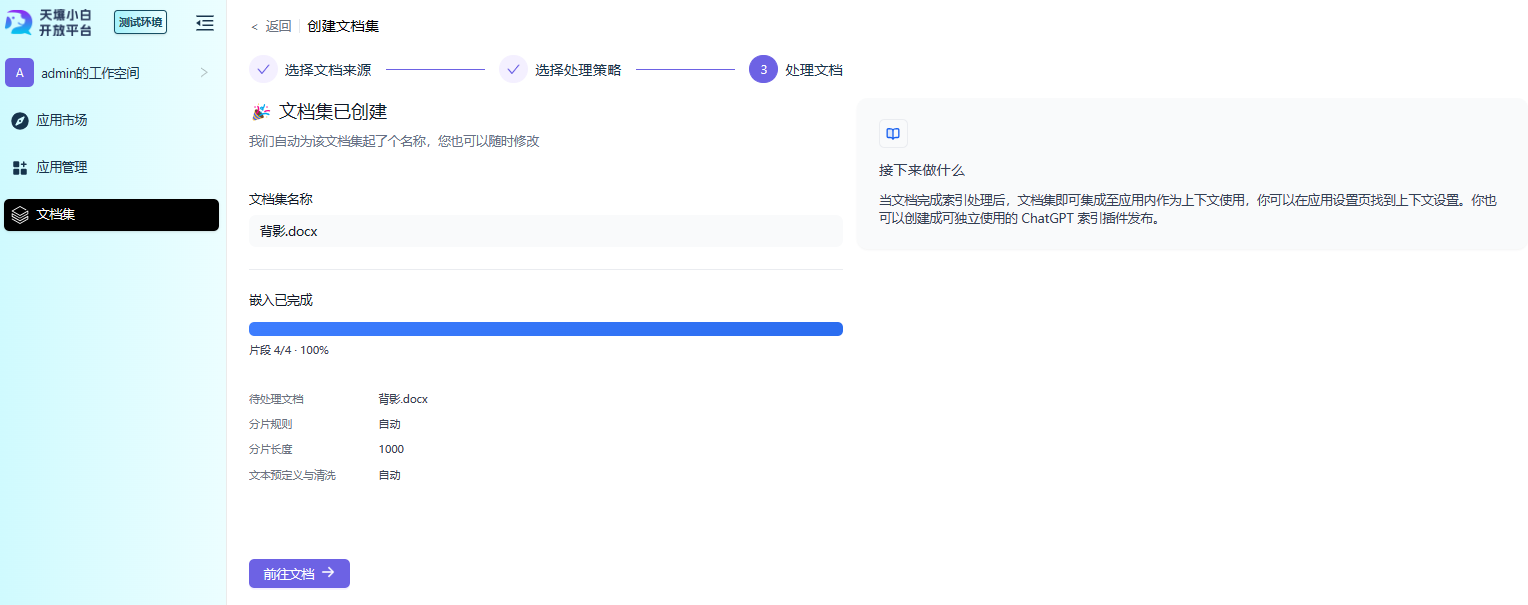
处理文档 #
上传文档,并设置处理策略后,系统会将文本嵌入为向量,并以分片形式存储在向量数据库中,通常该步骤在大模型中需要消耗 Token。
文档集设置 #
在文档集的上方导航中点击设置,你可以改变文档集的以下设置项:
文档集名称,用于识别一个文档集。
权限,可选择 只有我或所有团队成员,不具有权限的人将无法查阅和编辑文档集。
内容检索策略, 根据答案检索、根据问题检索。
集成至应用 #
文档集准备完成后需集成到应用中,当 AI 应用处理用户请求时,会自动将与之关联的文档集内容作为上下文参考。
进入「应用管理」- 「提示词编排」页面。
在上下文选项中,选择需要集成的文档集。
保存设置以完成集成。