模型接入
小白开放平台提供外部模型接入功能,接入的模型,包括语言模型(Chat)和嵌入模型(Embedding),必须满足小白的接口规范,并提供可访问地址供内部调用。用户可以在供应商页面基于小白模板新增供应商,并配置模型地址,完成后即可使用外部模型
自定义模型接入 #
新建模型供应商
模型供应商是模型的提供者,可以是天壤小白的模型,也可以是外部的模型,需要满足相应模型供应商的接入规范
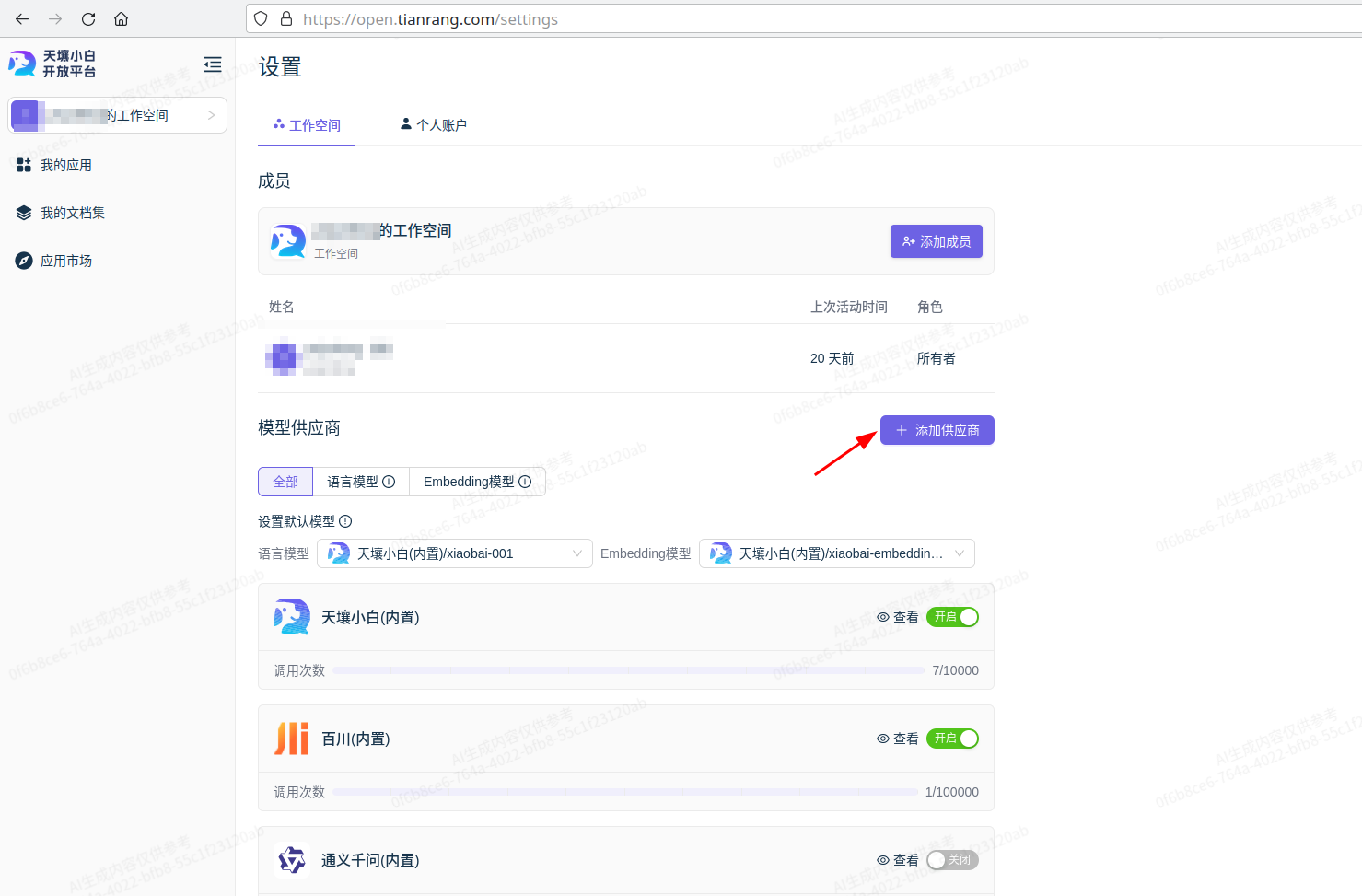
选择相应供应商模板, 填入模型供应商信息
接入的模型必须满足该模型供应商的接口规范,并提供开放平台可访问的调用地址以及其他必要信息
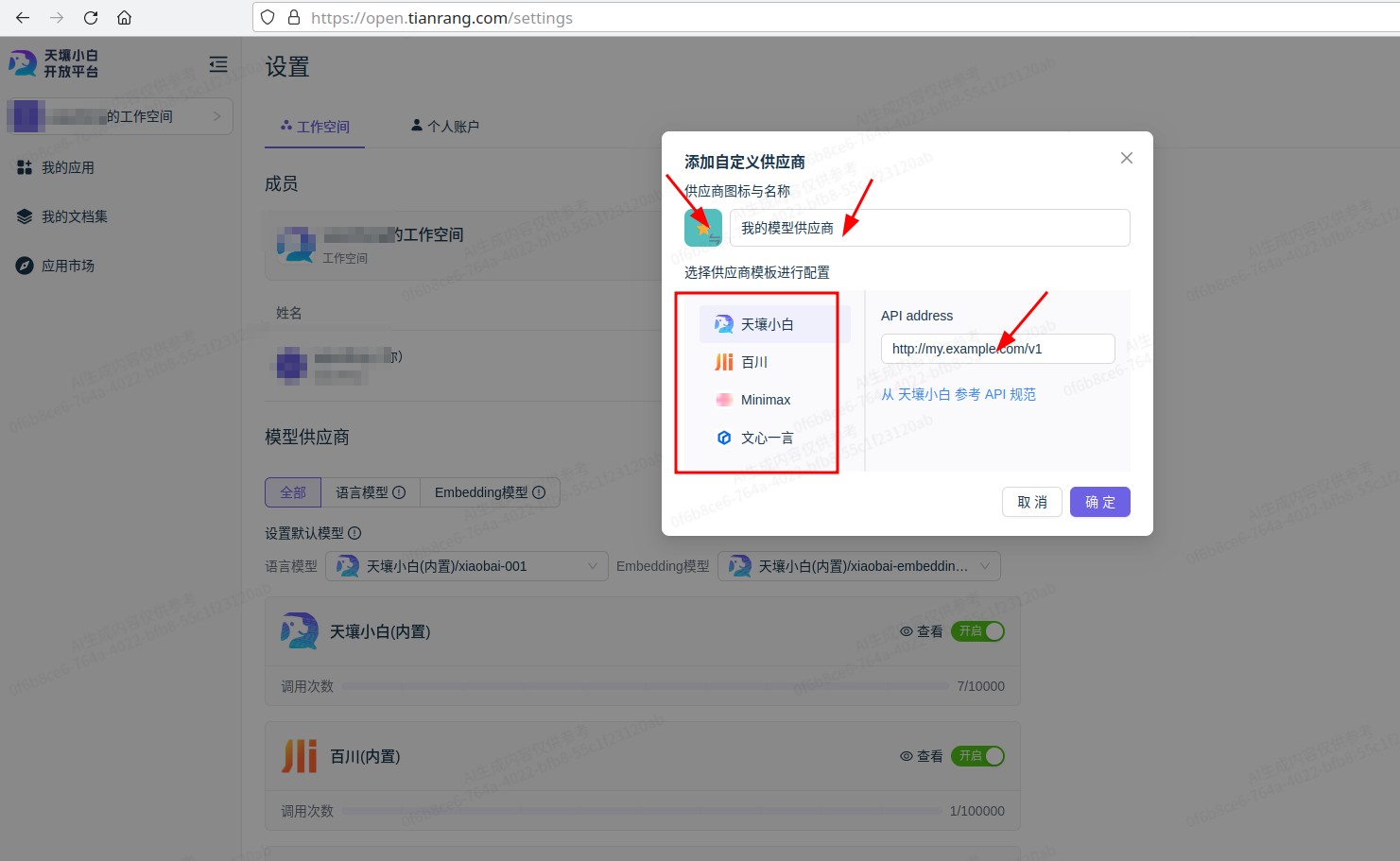
添加语言模型/嵌入模型
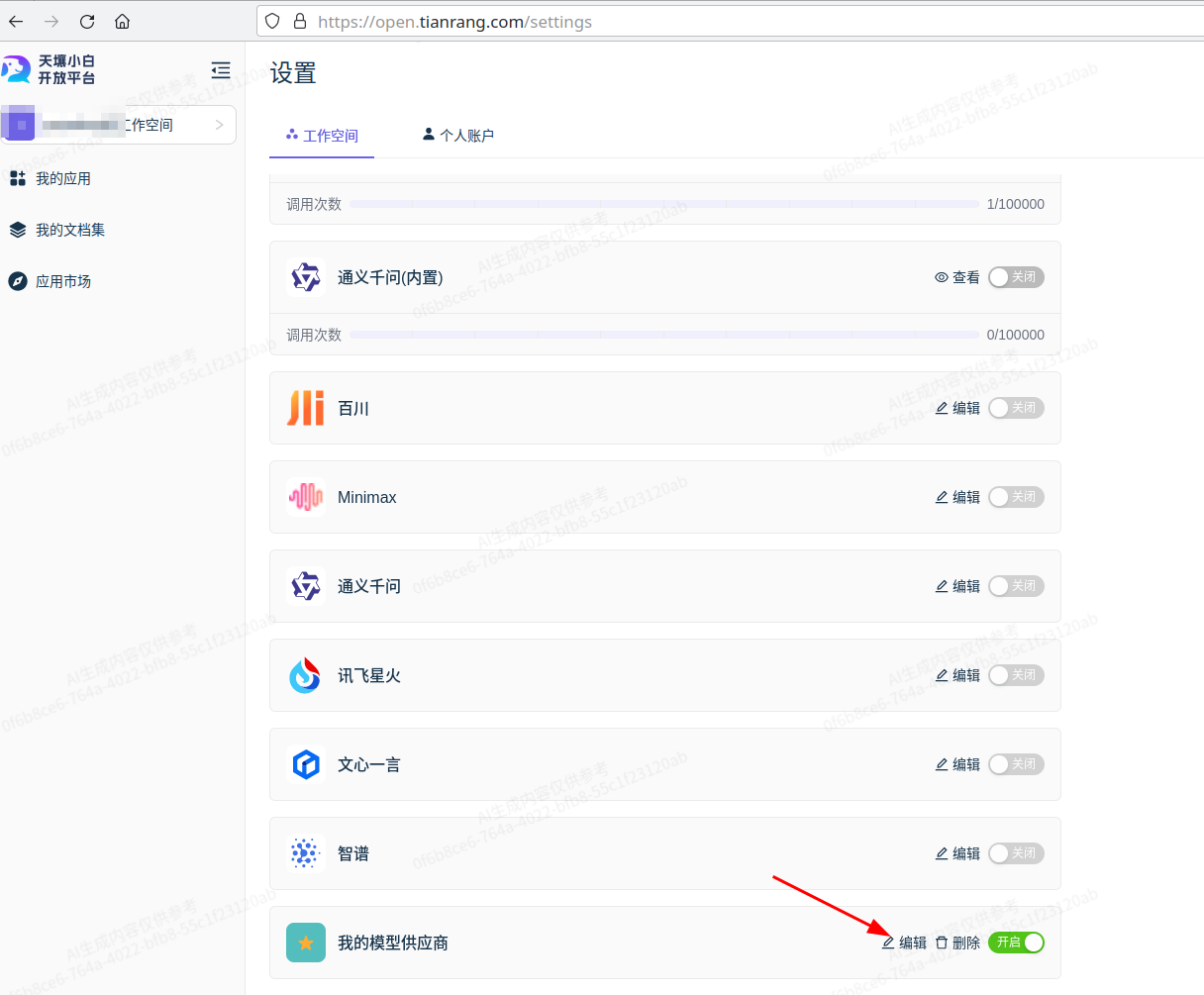
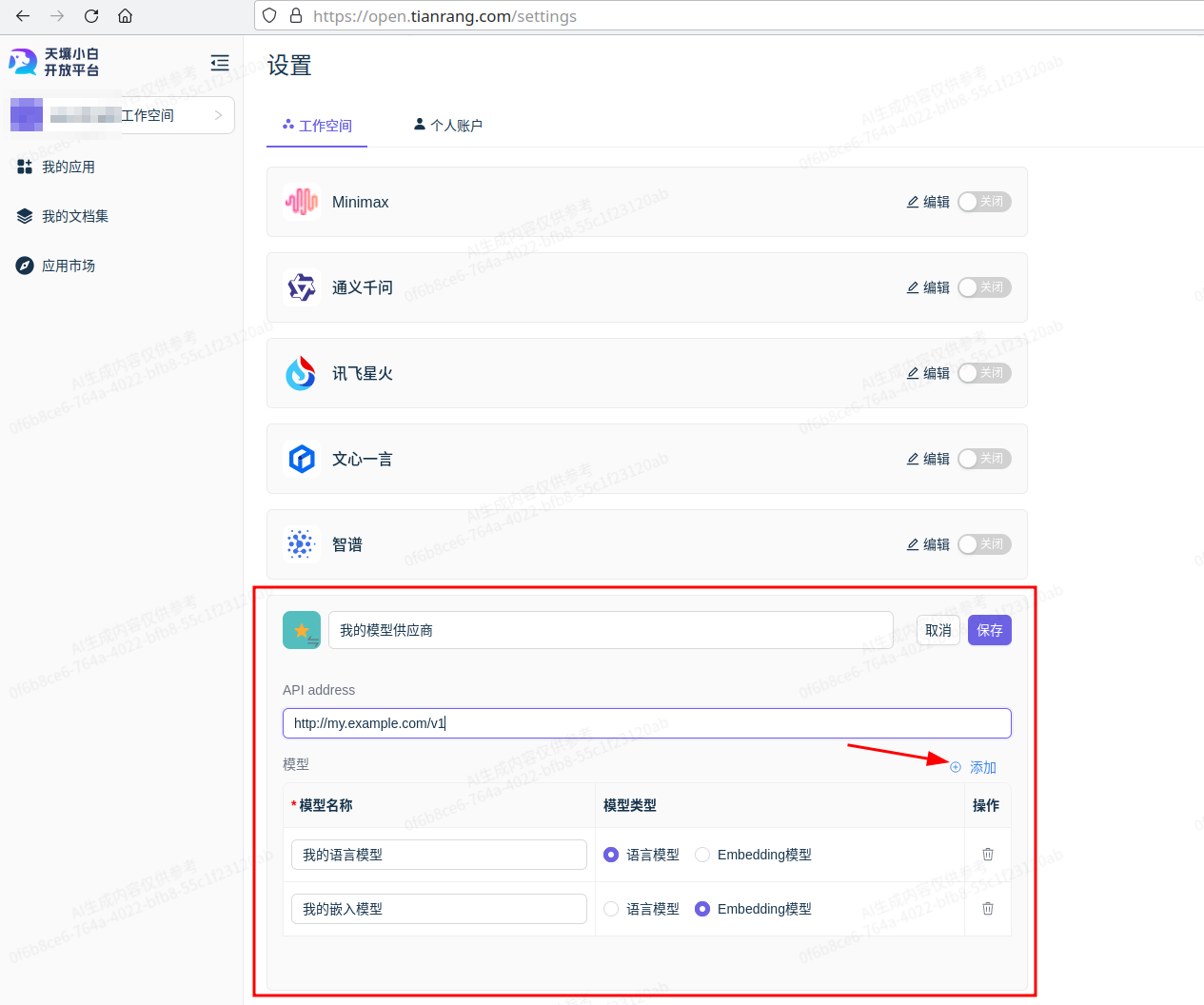
使用自定义模型
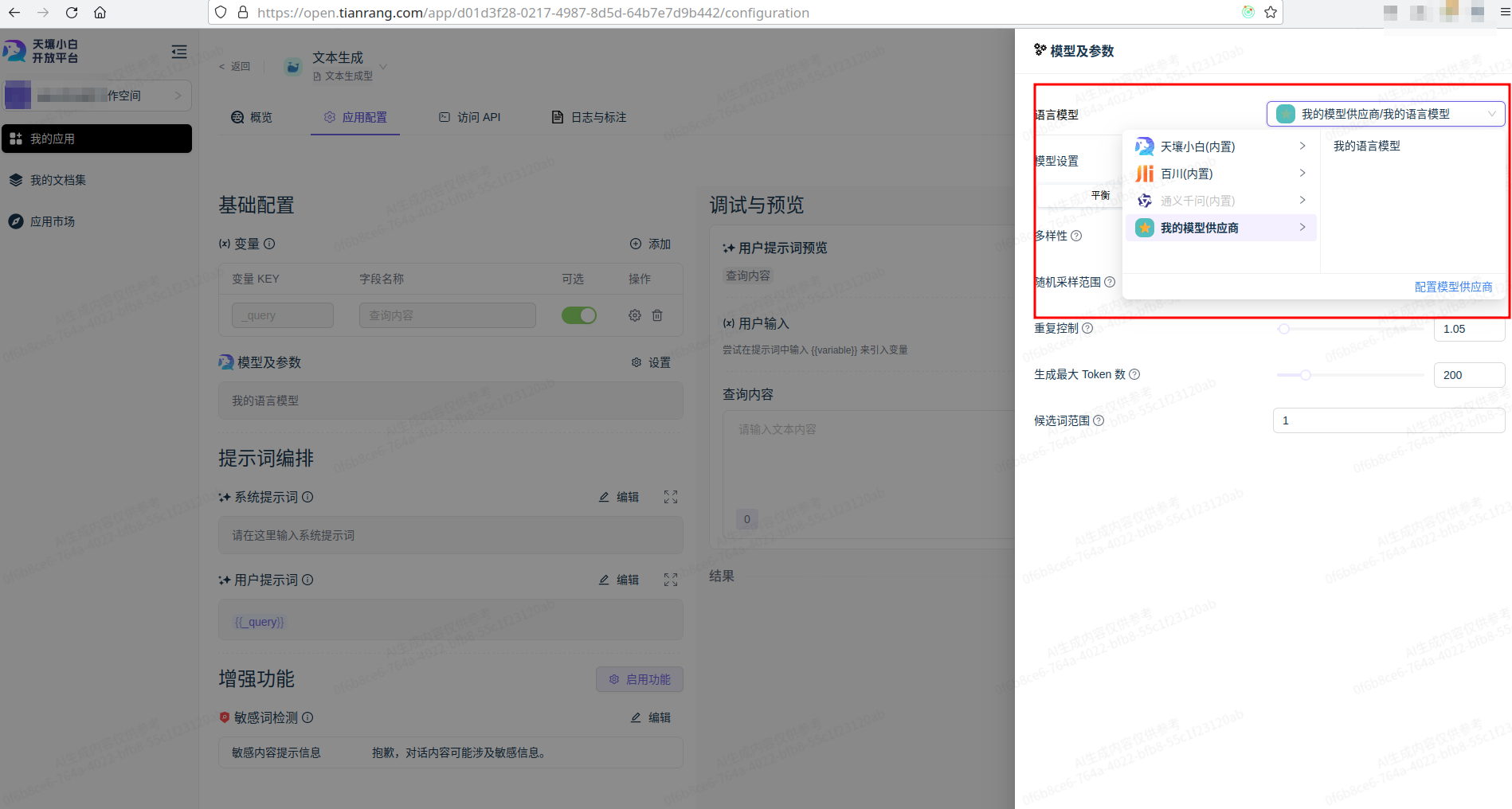
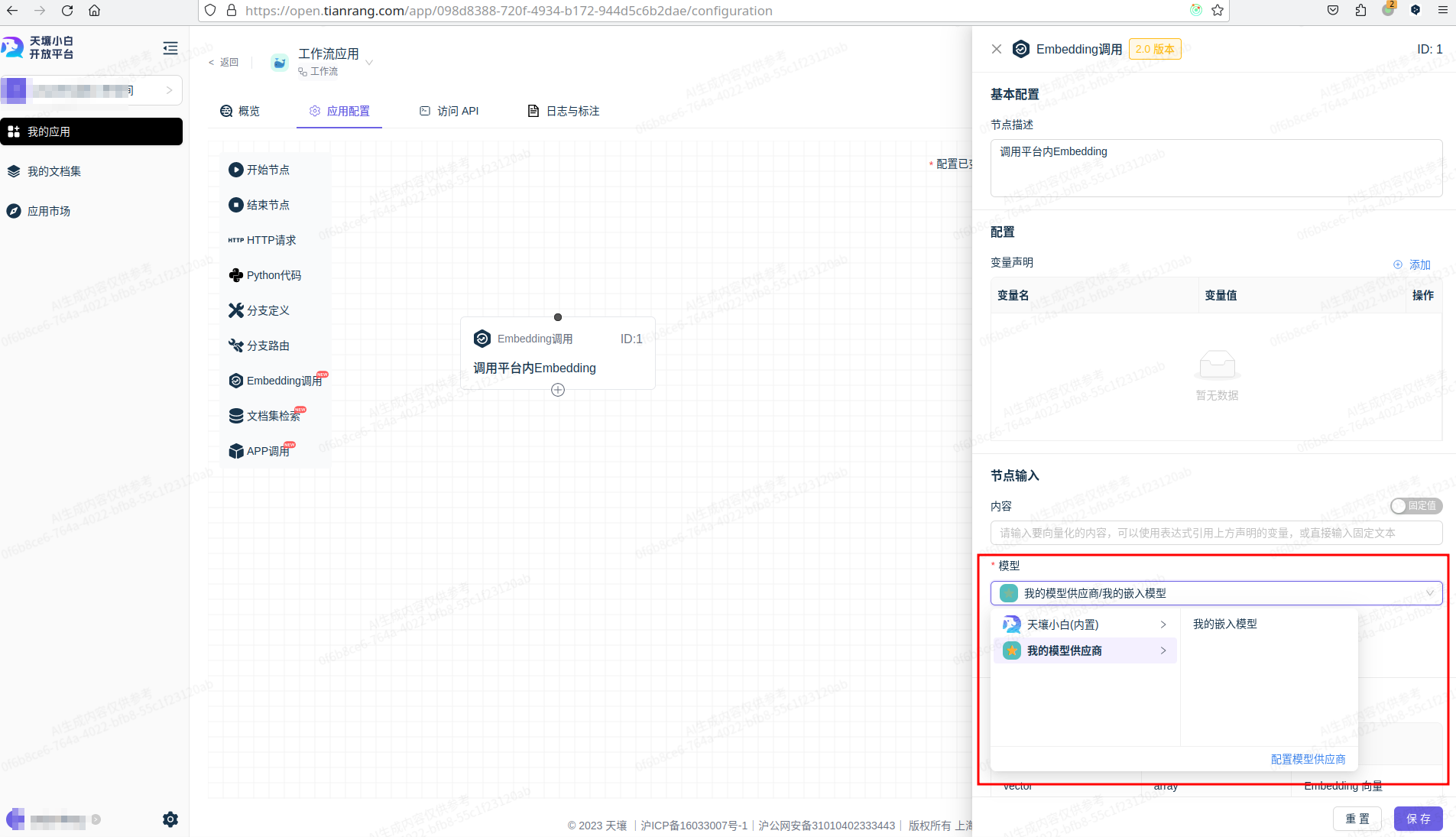
天壤小白模型接入规范 #
天壤小白模型接入规范约定了天壤小白模型供应商的API接口规范,供外部模型供应商参考
- 通过配置供应商中的模型地址(比如:http://host:port/v1 ),决定调用哪个模型服务
- 通过约定路由,决定调用哪种模型,比如:
- 实现 REST 路由
POST /vectors即可配置嵌入模型(Embedding) - 实现 REST 路由
POST /chat/completions即可配置语言模型(Chat)
- 实现 REST 路由
- 通过传入模型名称(model字段,json格式)作为请求参数,决定使用哪个模型(需要模型API内部自行实现)
语言模型 #
语言模型 API 文档 #
地址:POST ${base_url}/chat/completions
请求头:
Content-Type: application/json
请求参数:
| 参数名称 | 参数二级名称 | 类型 | 语义 |
|---|---|---|---|
| model | string | 模型名称 | |
| params | dict | 模型参数 | |
max_new_tokens | int | 最大输出token数 | |
temperature | float | 多样性,取值范围:[0, 1.0] | |
top_p | float | 采样比例,取值范围:(0, 1.0] | |
repetition_penalty | float | 重复控制,取值范围:(1, 2) | |
top_k | int | 采样范围,取值范围:(1,) | |
| messages | list | ||
role | string | 角色,system、assistant 或 user | |
content | string | 正文 | |
| stream | bool | 是否流式输出 |
非流式响应参数:
| 参数名称 | 类型 | 语义 |
|---|---|---|
num_query_tokens | int | 请求中文本的token数 |
choices | list[dict] | 对话输出 |
choices[0].message | dict | 对话输出消息 |
choices[0].message.role | string | 对话输出消息的角色 |
choices[0].message.content | string | 对话输出消息的正文 |
choices[0].num_generated_tokens | int | 对话输出消耗的token数 |
choices[0].finish_reason | string | 对话停止原因,包括 stop(正常停止)和length(达到最大长度停止) |
elapsed | float | 请求耗时,单位:秒 |
流式响应参数:
- 每行为一个 json,无前缀,直接用 json 解析
- 解析格式同
非流式响应参数,其中:choices[0].message未增量 token,非全量choices[0].num_generated_tokens为累计回答占用的 token 数
语言模型 API 调用示例 #
非流式 #
输入:
curl -X 'POST' \\ ${base_url}/chat/completions \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"role": "user",
"content": "hello"
}
],
"params": {
"max_new_tokens": 512,
"temperature": 0.01,
"top_k": 50,
"top_p": 0.95,
"repetition_penalty": 1.05
},
"stream": false
}'
输出:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "Hello! How can I help you today?"
},
"num_generated_tokens": 10,
"finish_reason": "stop"
}
],
"num_query_tokens": 13,
"elapsed": 0.2654237747192383
}
流式 #
输入:
curl -X 'POST' \
${base_url}/chat/completions \\ -H 'accept: application/json' \\ -H 'Content-Type: application/json' \\ -d '{
"messages": [
{
"role": "user",
"content": "hello"
}
],
"params": {
"max_new_tokens": 512,
"temperature": 0.01,
"top_k": 50,
"top_p": 0.95,
"repetition_penalty": 1.05
},
"stream": true
}'
输出:
{"choices": [{"message": {"role": "assistant", "content": "Hello"}, "num_generated_tokens": 1, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.09080147743225098}
{"choices": [{"message": {"role": "assistant", "content": "!"}, "num_generated_tokens": 2, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.10937714576721191}
{"choices": [{"message": {"role": "assistant", "content": " How"}, "num_generated_tokens": 3, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.12925171852111816}
{"choices": [{"message": {"role": "assistant", "content": " can"}, "num_generated_tokens": 4, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.14943981170654297}
{"choices": [{"message": {"role": "assistant", "content": " I"}, "num_generated_tokens": 5, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.16916155815124512}
{"choices": [{"message": {"role": "assistant", "content": " help"}, "num_generated_tokens": 6, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.19025135040283203}
{"choices": [{"message": {"role": "assistant", "content": " you"}, "num_generated_tokens": 7, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.2091517448425293}
{"choices": [{"message": {"role": "assistant", "content": " today"}, "num_generated_tokens": 8, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.2288496494293213}
{"choices": [{"message": {"role": "assistant", "content": "?"}, "num_generated_tokens": 9, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.250154972076416}
{"choices": [{"message": {"role": "assistant", "content": ""}, "num_generated_tokens": 10, "finish_reason": "stop"}], "num_query_tokens": 13, "elapsed": 0.2631406784057617}
嵌入模型 #
嵌入模型 API 文档 #
地址:POST ${base_url}/vectors
请求头:
Content-Type: application/json
请求参数:
| 参数名称 | 参数二级名称 | 类型 | 语义 |
|---|---|---|---|
| model | string | 模型名称 | |
| text | string | 输入文本 | |
| mode | string | 模式,query(单条请求)或passage(整个db),也可不区分,忽略此字段实现即可 |
响应参数:
| 参数名称 | 类型 | 语义 |
|---|---|---|
vector | List[float] | 嵌入向量 |
dim | int | 向量维度 |
tokens | int | 消耗token |
elapsed | float | 请求耗时,单位:秒 |
嵌入模型 API 调用示例 #
输入:
curl -X 'POST' \
${base_url}/vectors \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "xiaobai-embedding-002",
"mode": "query",
"text": "hello"
}'
输出:
{
"vector": [
0.026604672893881798,
-0.018825825303792953,
-0.0024815492797642946,
-0.04342295974493027
],
"dim": 4,
"tokens": 6,
"elapsed": 0.06209564208984375
}