天壤文本嵌入(Text Embedding)模型
❓什么是文本嵌入(Text Embedding) #
嵌入(Embedding)是一种将高维数据映射到低维空间的技术,常见于机器学习和自然语言处理(NLP)领域。文本嵌入(Text Embedding)的目标是将文本中的词表示成固定长度的稠密向量,也称为词向量(Word Vector)。这样每个词都可以用一个连续的、低维的稠密向量来表示。文本嵌入的主要目的是捕捉每个词的语义信息,使得语义相关的词在嵌入空间中距离较近,不相关的词距离较远。这样就可以用向量间的距离来表示词之间的语义关系。与高维稀疏表示(如TF-IDF)相比,文本嵌入具有克服词汇不匹配问题和促进高效检索和匹配的潜力。通过文本嵌入,单词之间的语义关系可以在向量空间中得以保留。好的文本嵌入模型能够捕捉到单词在上下文中的语义信息,有助于提高自然语言处理任务的性能。
基于Embedding的语义检索方式对比关键词检索的优势 #
⭐️ 语义理解: 基于 Embedding 的检索方法通过词向量来表示文本,这使得模型能够捕捉到词汇之间的语义联关系,相比之下,基于关键词的检索往往关注字面匹配,可能忽略了词语之间的语义联系。
⭐️ 容错性: 由于基于 Embedding 的方法能够理解词汇之间的关系,所以在处理拼写错误、同义词、近义词等情况时更具优势。而基于关键词的检索方法对这些情况的处理相对较弱。
⭐️ 多语言支持: Embedding 方法可以支持多种语言,有助于实现跨语言的文本检索。比如你可以用中文输入来查询英文文本内容,而基于关键词的检索方法很难做到这一点。
⭐️ 语境理解: 基于 Embedding 的方法在处理一词多义的情况时更具优势,因为它能够根据上下文为词语赋予不同的向量表示。而基于关键词的检索方法可能无法很好地区分同一个词在不同语境下的含义。
对于语境理解来讲,人类使用词语和符号来交流语言,但是孤立的单词大多没有意义,我们需要从共享的知识和经验中汲取,才能理解它们。比如“你应该百度一下”这句话,只有在你知道百度是一个搜索引擎,并且人们一直在使用它作为动词时才有意义。同样地,对于有效的自然语言模型来说,也要能够以理解每个单词、短语、句子或段落在不同语境下可能的含义。
天壤文本嵌入(Text Embedding)模型介绍 #
天壤自研的文本嵌入(Text Embedding)模型(以下简称’天壤Embedding模型’),能够将文本数据转换为高维向量表示,将具有相似含义的文本存储于非常接近的位置,以此来精准捕捉文本词汇、语义和上下文信息。适用于摘要、推荐、寻找相似内容、语义搜索和分类等多种文本处理任务。与传统的关键词搜索相比,向量搜索结果更快、更准确。通过天壤Embedding模型,将企业文档进行语义向量化预处理,能够帮企业快速构建知识库、推荐系统、搜索引擎或任何需要在大型数据集中查找相似项目的应用。
🚀 模型优势 #
优秀的中文嵌入支持
模型基于大量中文语料数据进行训练,能够充分理解丰富的中文语言知识,掌握多种不同的文体和方言,包括书面语、口语、新闻语言等,从而更好地捕捉中文语境下的语义信息。在文本分类、命名实体识别、机器翻译等中文自然语言处理任务中性能表现优异。
多语言处理
基于大模型训练的多语言嵌入模型,具有4096维的向量表示,创造了丰富、通用的语言表示向量,支持不同语言在向量空间上的相互搜索而无需翻译,使得文本理解、分析等各种语言任务更准确和高效。
📌 应用案例 #
多语言语义搜索: 文本嵌入可以精准捕捉文本数据的含义和上下文,更理解用户意图,结合向量搜索引擎以及最近邻搜索技术,可以快速准确找到与用户搜索相关的内容,提高搜索准确性。
个性化产品推荐: 文本嵌入模型可以识别相似文档数据以及嵌入空间的向量,可用于个性化产品推荐。通过分析用户历史行为和偏好,向用户推荐购买相同产品的同类型用户喜欢的其他产品,或根据不同标签、指标对产品推荐进行排名。
跨语言内容审核: 文本嵌入模型结合分类以及聚类算法,可以同时处理多种语言,准确地检测、过滤和审核在线内容,而无需为每种语言构建独立的审核模型,确保用户生成的内容符合平台政策和条规。
📚 大语言模型知识扩展 #
大语言模型有两种方式可以学习新知识:
方式1:模型微调
方式2:模型输入,即将知识作为上下文提示词输入给模型
尽管微调可能感觉更自然,毕竟数据训练是大语言模型学习所有知识的方式,但微调在事实回忆方面并不可靠。类比一下,把大模型比作一个参加考试的学生,模型权重就像长期记忆,当你对模型微调时,就像提前一周准备考试,当考试来临时,模型可能会遗漏掉之前学习过的知识或者错误地回答出从未教授给他的知识。而使用Embedding的方式,这个学生在考试前什么都不需要准备,在考试时带着一份小抄进了考场,需要回答的问题的时候,就低头看下准备好的小抄,照着小抄来答题相比于记忆(微调)肯定更准确。并且考完试就直接把小抄丢掉,也不用占用任何记忆,整个过程简单易行(对技术实现来讲也是如此)。
不过这种临时翻看小抄的方式也有限制,每次参加考试,这个学生只能带进几页小抄,不可能把所有教材笔记带进考场,这是由于大模型单次输入的词数限制。
所以当数据量远远超过这个词数限制的时候怎么办呢?这就要引入基于 Embedding的语义检索 + 上下文注入提问的方案。
🧿 如何使用 #
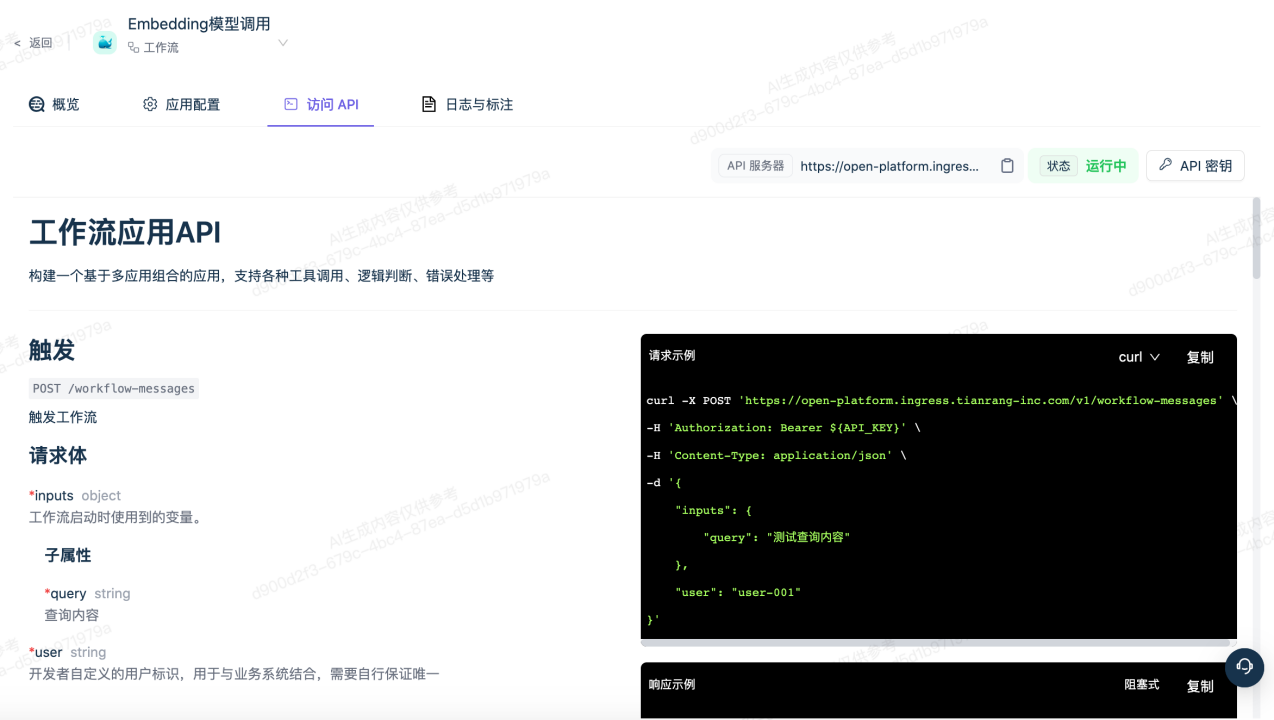
天壤Embedding模型的调用,可通过天壤小白开放平台的工作流应用中,使用Embedding调用组件实现。
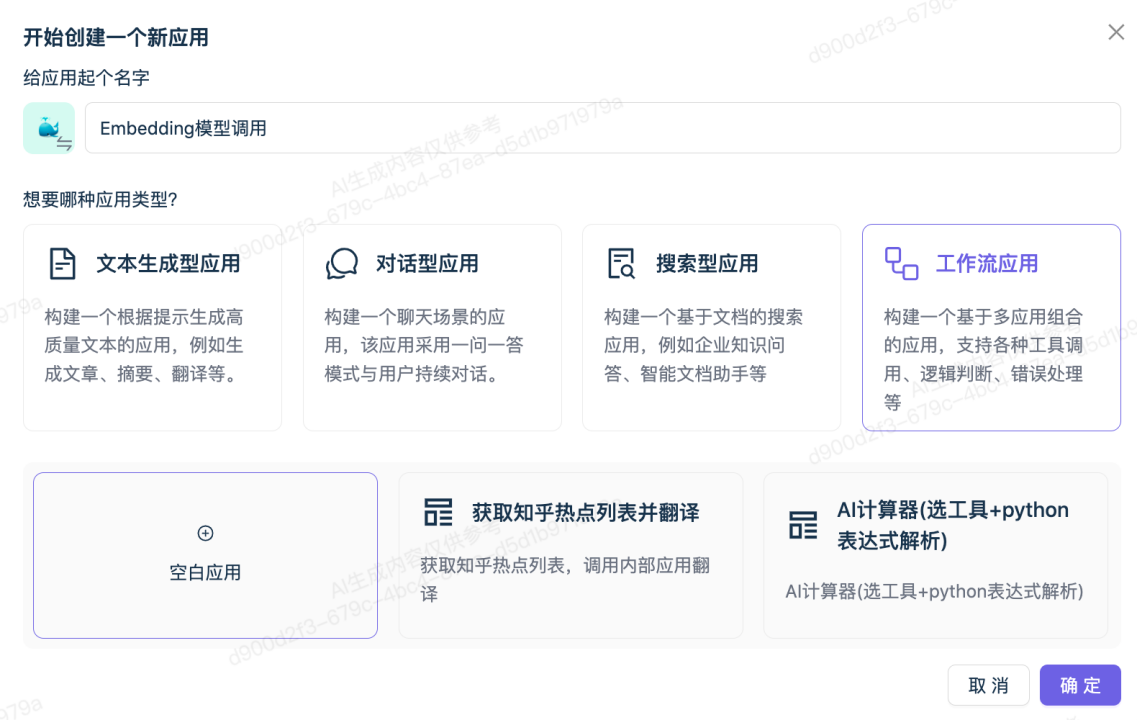
1.创建工作流应用
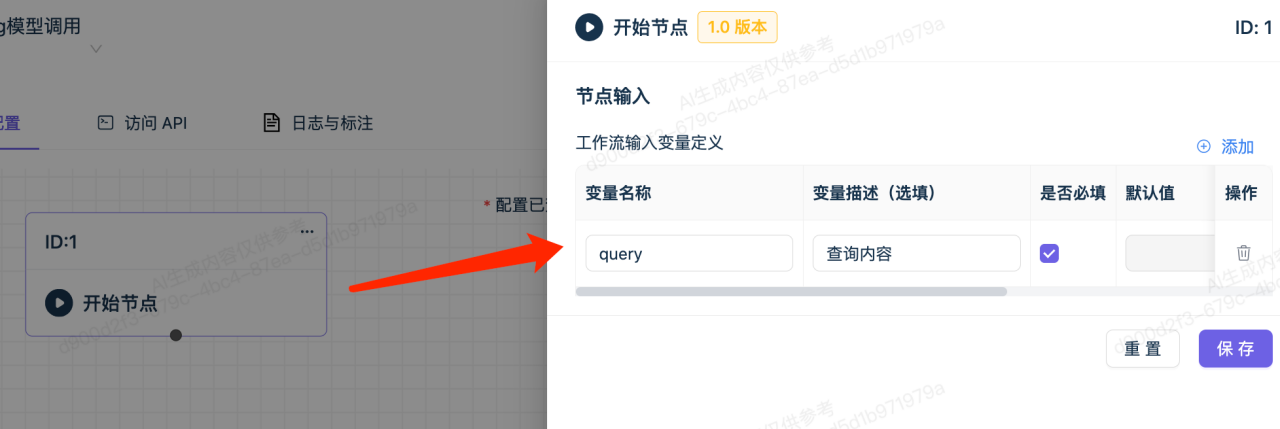
2.添加开始节点,并配置输入变量
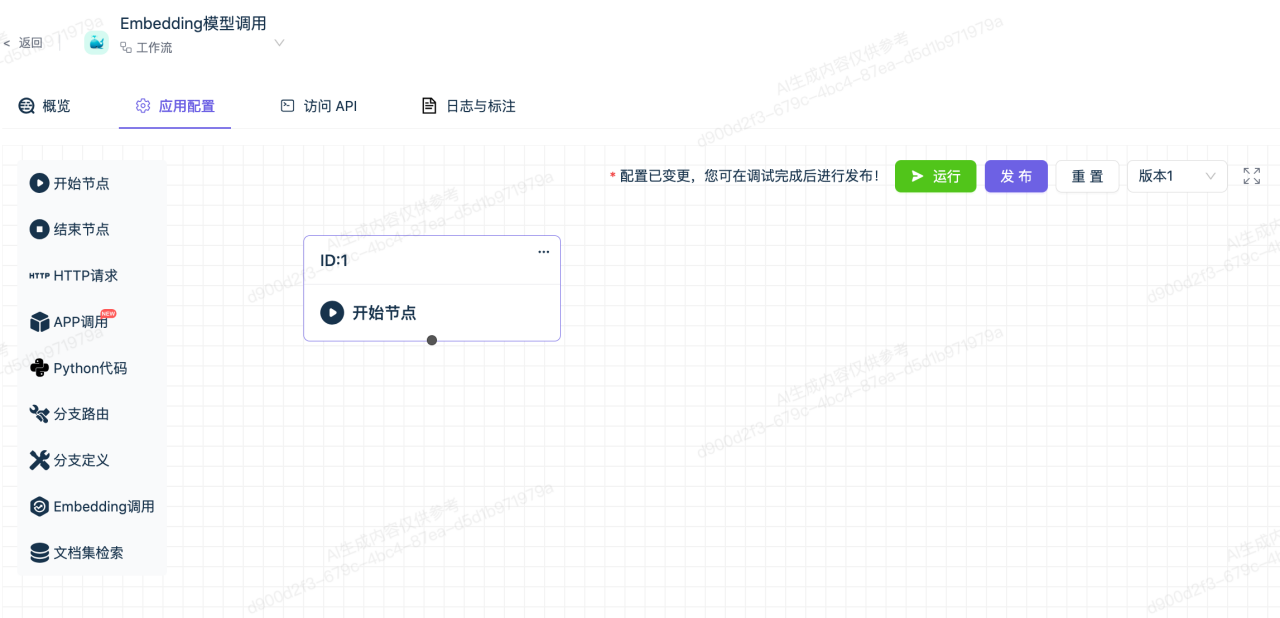
3.配置Embedding模型调用节点
在此节点中设置需要向量化的内容,使用天壤Embedding模型
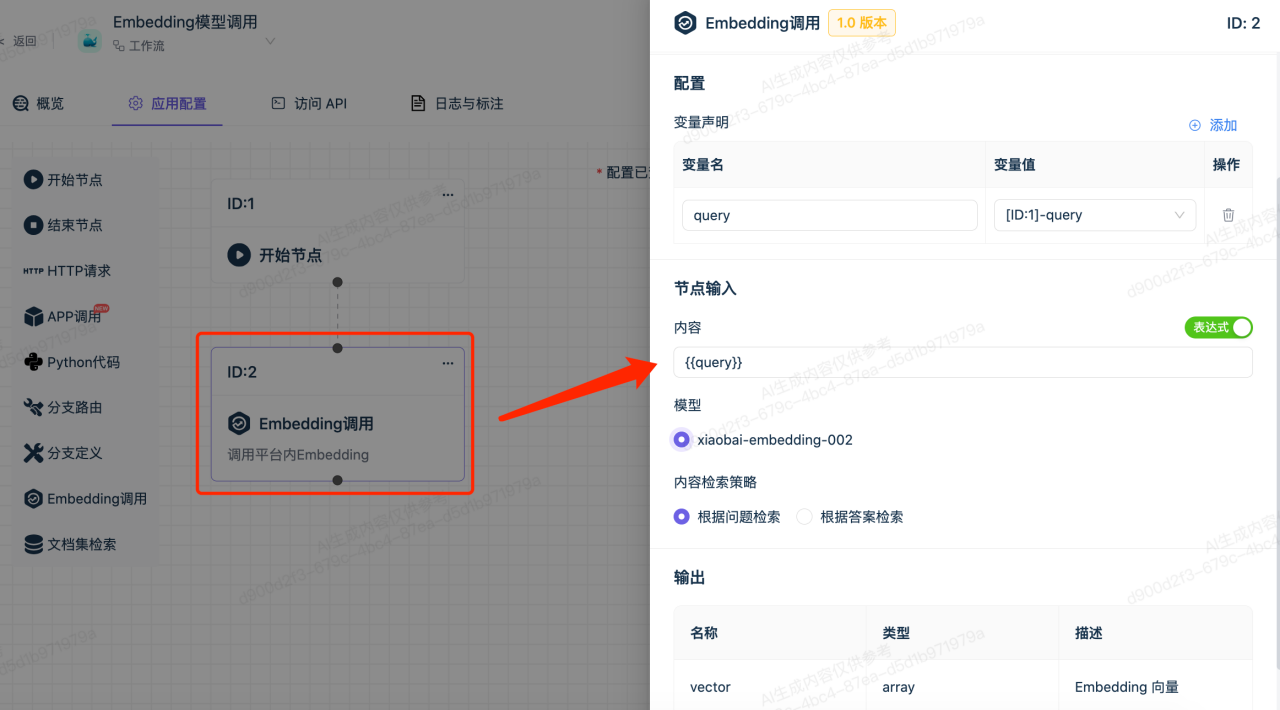
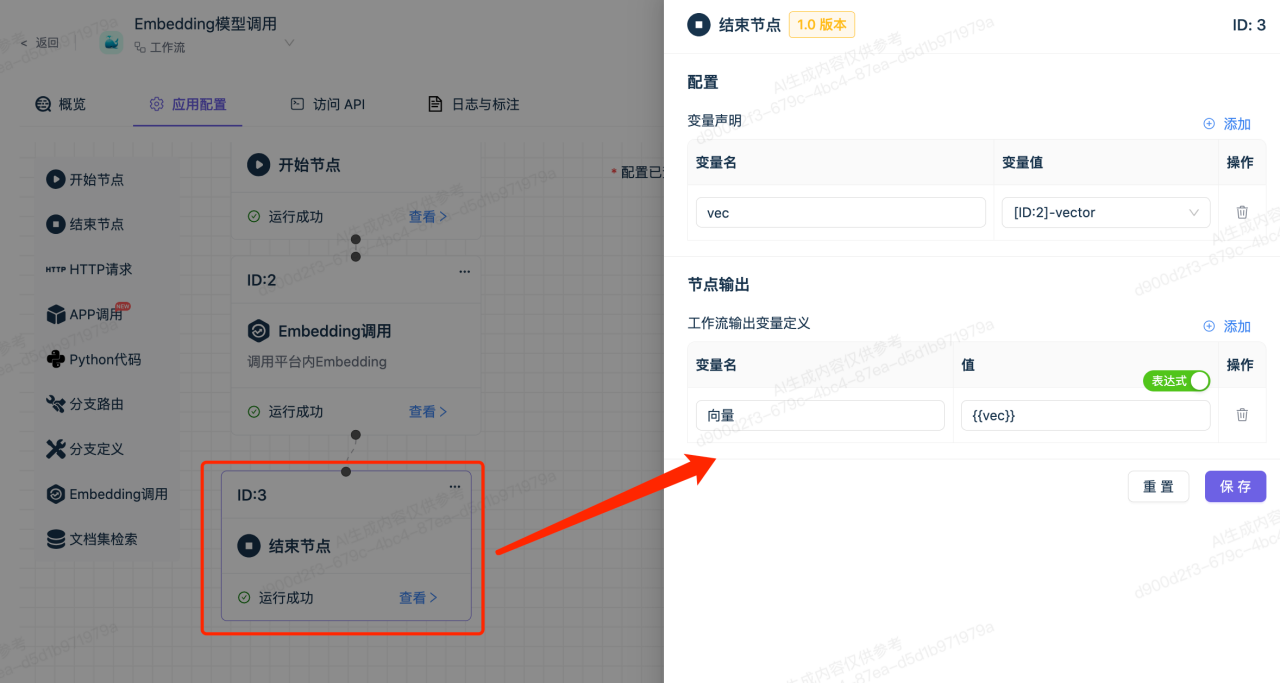
4.配置结束节点
在结束节点中设置需要输出的变量,如下图示例,仅输出文本的向量
5.运行调试
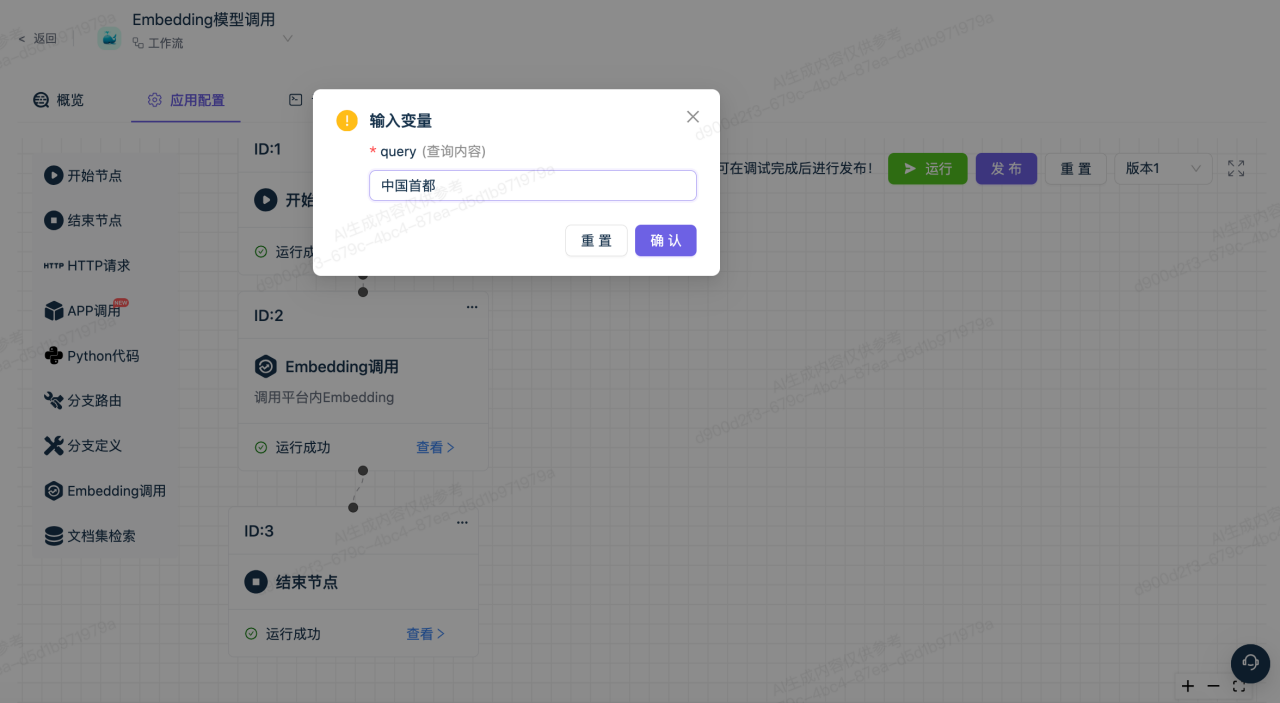 查看每个节点的输入输出内容
查看每个节点的输入输出内容
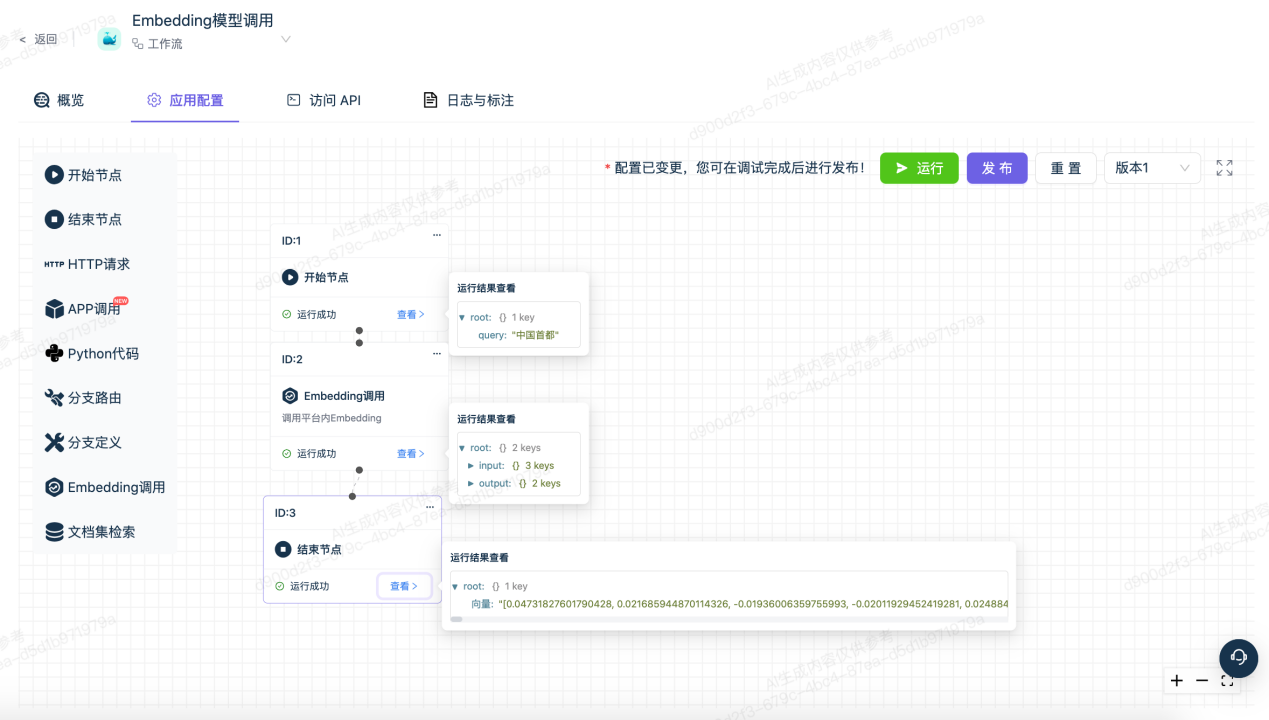
6.调试成功后,可以将其发布为Web站点
天壤Embedding模型支持多种主要语言,包括但不限于英语、中文、西班牙语、法语、德语等。这意味着您可以在全球范围内使用我们的模型,为多语言用户提供高质量的文本向量化服务。
如下图所示,输入“你好,世界”,输出向量表示;
下图为英语向量化示例,输入“你好,世界”的英文翻译:
下图为法语向量化示例,输入“你好,世界”的法语翻译:
7.通过API方式调用Embedding模型
我们提供了简洁而强大的API,你可以将天壤Embedding模型轻松集成到任何应用终端程序中。不论你正在开发智能搜索引擎、情感分析工具、推荐系统,还是其他文本相关的应用,都可以通过简单的API调用实现文本向量化功能,为你的应用增加智能和高级功能。